
Technology Services
In the globalized competitive economy coupled with capabilities, Information technology has emerged as a key component of competitive advantage. Technology Services ...
Learn MoreThis approach results in year-over-year reductions in your eDiscovery costs of 40 to 70 percent.
Equipped to service all your eDiscovery data processing needs we help you address the riskiest and costliest areas of collecting, preserving and reviewing electronic information for legal matters by delivering the right balance of people, processes, technology and controls. We help automate your e-Discovery needs ensuring timely and accurate delivery of the requested information resulting in year-over-year reductions in your e-Discovery costs of 40 to 70 percent.
A Product Company driven by innovation and passion that has delivered class-leading e-Discovery solutions powered by our expertise in Machine Learning and Artificial Intelligence based Data Science. Additionally, we have products across education, fitness, online reputation, lease and account management domains. We also specialize in solutions using GIS and Block Chain technologies.
We are setting new standards for eDiscovery excellence. Our electronic discovery services leverage complex and state of art algorithms that crunch data at a more efficient and reliable rate giving you un-paralleled confidence in the outcome while significantly cutting costs.
With a large network of subject-matter experts and professionals, Sageable's electronic discovery services reach worldwide and support multifaceted, international eDiscovery projects.
Big Data is a set of data-sets which are complex that cannot be dealt with traditional data processing and application software. Big data challenges include capturing data, data storage, visualization, data analysis, search, sharing, transfer, querying, updating and information privacy. Big Data term refers to use of predictive analytics, user behaviour analytics and other advanced data analytics to extract value form the large set of data available. The characteristics of Big data are Volume, Variety, Velocity, Variability, Veracity. The main components of big data are
Driven by specific investigation system and software, big data can point information that indicate the way different business benefits, including new opportunities, better client benefit, enhances effectiveness of operations and upper hands over rivals.
We combine both domain and technical knowledge in solving business problems using cutting edge technologies that enable outcome driven analytical solutions.

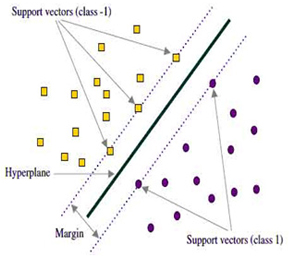
The functionality of SVM is it splits a single input subset of documents into two other distinct subsets.
The SVM algorithm learns to distinguish between the two categories based on training a set of documents that contains labelled examples from both categories. This separating line is recorded and used for classification of new documents. New documents are mapped and classified based on their position with respect to the model. Apart from SVM, we also use advanced classifiers like Random Forest, Neural Network and Ensemble Learning.
There are many ways to reduce a document to a vector representation that can be used for classification. Word2Vec is one of the popular vector representation of text data we use in our solution for document classification.
Predictive Coding is very important to identify documents related to specific case or investigation. Predictive modelling solves a use case where in when you want to find out if a particular document is relevant to a specific topic.
Predictive Coding helps to scan electronic documents that are related to a legal case by using Artificial Intelligence programming and some mathematical models through searching by Keywords. Predictive Coding helps cost savings and facilitates a quicker and more effective review process.
Documents can be reviewed as an alternative to contracting an attorney review. Each model is completely customized for the issue and the dataset at hand. Predictive coding is not restricted to coding for responsiveness and benefit – topic specialists can prepare the framework for any related issue. Once a model is run against the entire corpus of available documents, the population is winnowed down to a manageable size for more senior lawyers to review.
Topic Modelling/Clustering is a technique in the field of text mining to automatically identify topics present in a text object and to derive hidden patterns exhibited by a text corpus. Thus, assisting better decision making.
Topic Modelling is different from rule-based text mining approaches that use regular expressions or dictionary based keyword searching techniques. It is an unsupervised approach used for finding and observing the bunch of words (called “topics”) in large clusters of texts.
This is frequently used for filtering out the hidden semantic structures in a document. Topic Modelling helps for document clustering, organizing large blocks of text documents, betterment of information from different documents.
BigARTM algorithm is used to generate a statistical model to discover topics in a collection of documents and is used to mine text to enable easier reviews. The process can create word clouds that enable reviewers to quickly process the topics/gist thereby enabling faster reviews.
Email Threading identifies people involved in a conversation that includes running list of all replies starting with the original email, responses and forwarded emails. Wide usage of email threading will increase efficiency and can directly focus on most essential replies.
Email metadata and text extraction using applications such as Aspose or Oracle OpenText and creation of threads based on conversation index enables processing email conversations and related information.
Near Duplicates are the documents that are nearly same but not exactly so. This helps to view the near duplicates of previous legal documents where a few typos were fixed or a few sentences were added.
For e-discovery we want to group similar documents which are mostly the same, which might reveal important information. The differences in the documents are shown as highlighted text. This algorithm measures how similar both the documents are between 0-100%.
Popular algorithms like MinHash, Jaccard Similarity can be used to detect near dupes from a collection of documents apart from identifying exact duplicates too.

In the globalized competitive economy coupled with capabilities, Information technology has emerged as a key component of competitive advantage. Technology Services ...
Learn MoreMake better, smarter business decisions more quickly and confidently with solutions designed to drive business value across your entire organization ...
Learn MoreLarge budget project? Tight schedule? What about a new complex business opportunity? Let Sageable Technologies tailor a recruitment process to meet ...
Learn MoreWe believe that with the shrinking differentiation from enterprise software, "Analytics" is the frontier to create strategic advantage for businesses ...
Learn MoreSageable is your one-stop shop for all things IoT. Our teams of strategic consultants, engineers and system architects have deep experience in complex ...
Learn MoreCloud Computing is a technology that uses the internet and central remote servers to maintain data and applications. Cloud computing allows consumers ...
Learn MoreSageable's eDiscovery Solutions We help you address the riskiest and costliest areas of collecting, preserving and reviewing electronic information for ...
Learn MoreSageable Techonologies had the opportunity to get trained and work on Accela product. As an initiative, Sageable built a COE around this Product.
Learn More